一开始,总想着把位姿更新里加入角速度和加速度之类的,还是更新一个位姿,但是怎么也做不出媲美livo2在golbal shutter模式下的效果。
想法:elastic slam,and msckf
elastic slam such as ct-icp,基于优化的,同时优化雷达帧的开始和结束位姿。
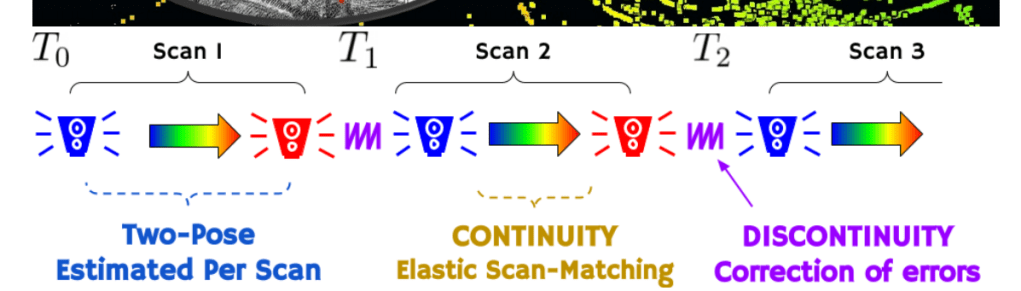
msckf:通过在滤波状态中维护多个时间的位姿克隆,使一个视觉测量同时约束多个状态,并通过消元把“非状态变量(特征)”的影响折叠进状态更新。
对于rolling shutter,其实一个视觉测量就是可以约束多个姿态,也就是可以简单的把rs的姿态设定为两个,开始姿态和结束姿态。
最终方案的核心:
- 每帧 RS 图像内部只有两端时刻:Ts(第一行曝光时刻,start)与 Te(最后一行曝光时刻,end)
- 在滤波状态里显式加入一个 pose clone:(Rs,ps) 与主状态的(Re,pe) 共同描述 RS 内的连续位姿
- RS 观测用 两端位姿插值 + 固定点迭代满足隐式 RS 约束
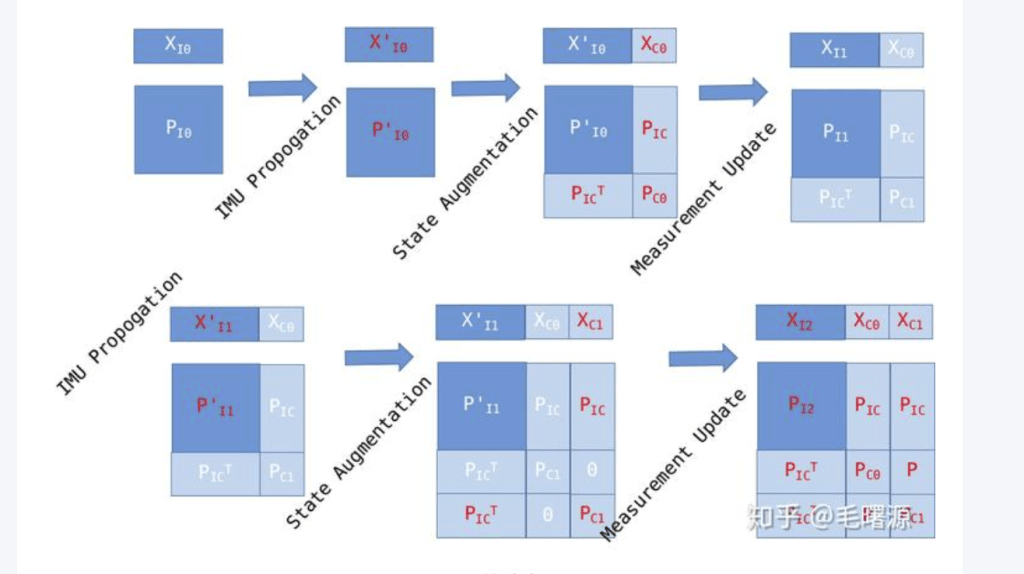
- 传播时用MSCKF 的方法在Ts 处扩维并建立cross协方差
- 视觉更新后对 clone 进行边缘化,把 RS 信息折叠回主状态,然后删掉 clone,进入下一帧
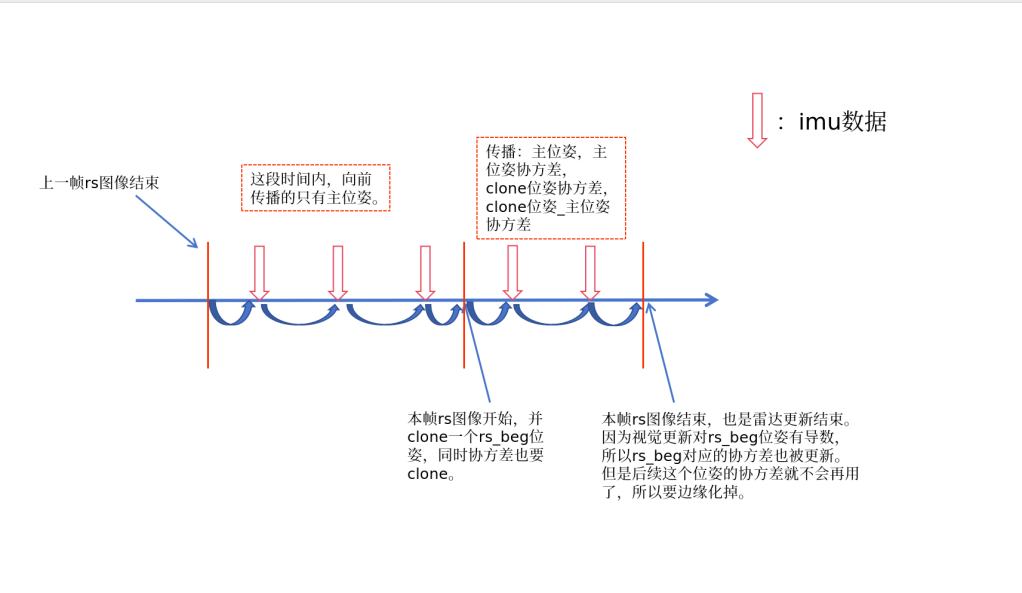


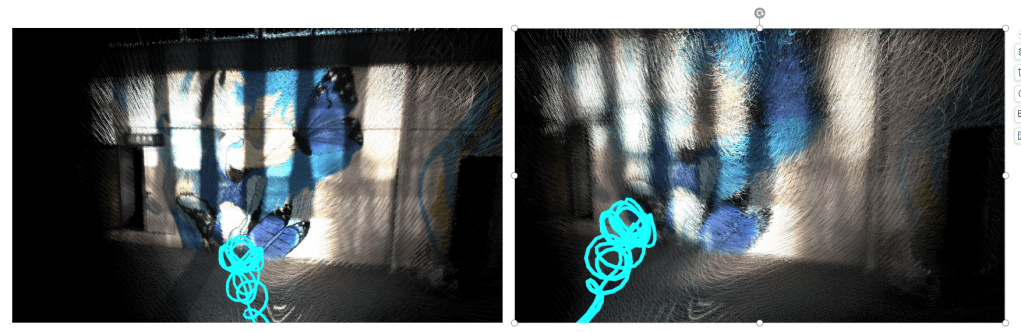
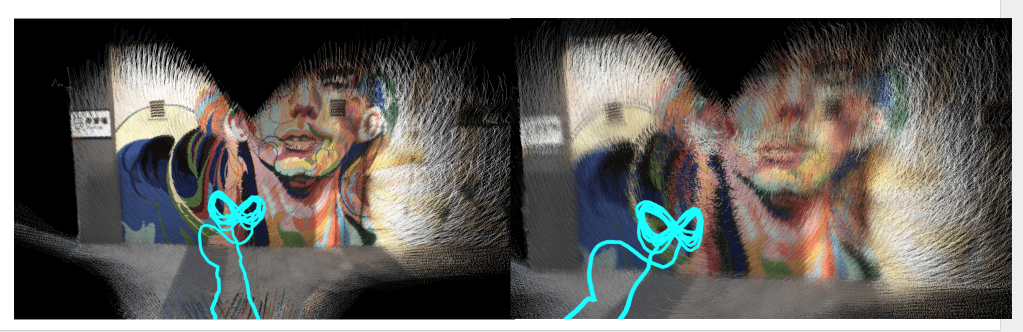
对于自适应位姿clone,主要的问题是如何判断要插入一个clone位姿。对于rs来说,旋转的影响更大,而我们的模型里,两个clone位姿之间是slerp插值,所以当角加速度过大的时候,位姿插值就会不准确。
通过设定最大角度误差的值,推算最大可接受的角加速度,通过这个来确定要不要加入位姿。
后续也可以加入平移上界,不过目前看来够用了。

对于图像去畸变:



rolling shutter aware neuvox
方法:
原始方案中,体渲染沿射线采样空间点,查询体素网格得到颜色与密度,经体渲染方程积分为像素颜色。核心假设是一张图所有像素共享同一相机位姿,所有射线从同一原点、按固定朝向发出。
但卷帘快门相机逐行曝光,曝光期间相机持续运动,不同行实际对应不同位姿。若仍用单一位姿生成射线,会引入系统性几何误差,产生条纹伪影和几何失真。
本次改造为每张图像引入多个行级锚点位姿,训练时根据像素行号在相邻锚点间做插值,得到逐行专属位姿并据此生成射线。体渲染流程本身不变,仅射线的起点与方向更贴合真实成像过程。
